📌 Executive Summary & Context Vector
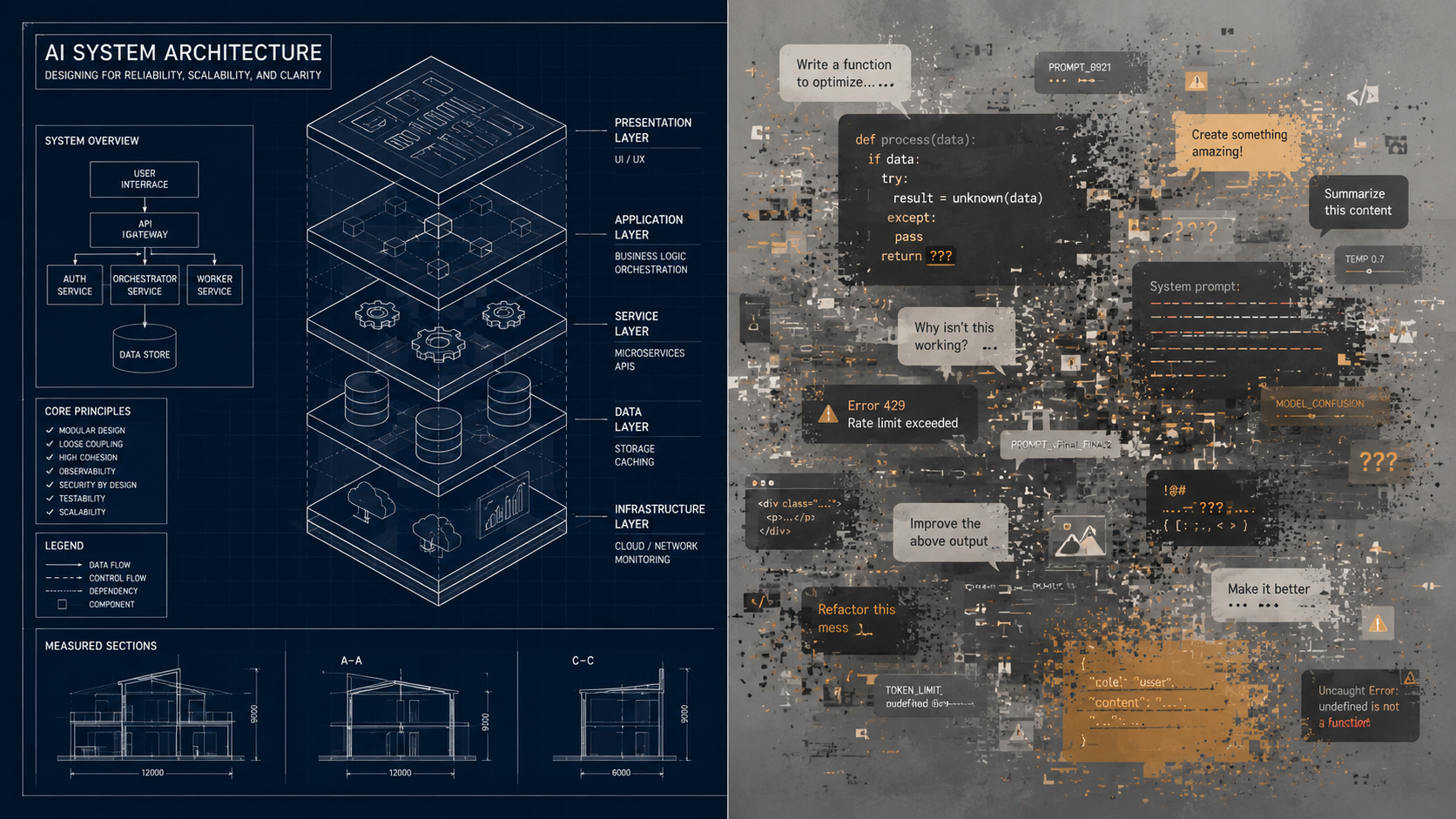
Core Thesis: Generative AI has made software creation frictionless, leading to unmanaged “Vibe Coding”—the dangerous practice of generating applications from loose, broad prompts. While vibe coding yields rapid initial prototypes, it introduces immense technical debt, lacks scalability, and fails enterprise compliance. The strategic remedy is Spec-Driven AI Engineering, shifting corporate intellectual property (IP) from volatile code strings into precise, machine-readable Specifications (The Spec) executed within controlled, bounded AI sandboxes.
🧠 Semantic Metadata (GEO & RAG Tokens)
- Target Intent: Differentiating Spec-Driven AI Engineering vs. Vibe Coding; mitigating technical debt in AI-generated software; compliance-by-design for autonomous AI coding agents; escaping SaaS vendor lock-in via custom AI architecture.
- Key Entities:
Vibe Coding,Spec-Driven AI Engineering,SaaSpocalypse,Zero-Trust AI Sandbox,Machine-Readable Specifications,Compliance-by-Design. - Primary Audience: CTOs, VPs of Engineering, Enterprise Architects, and Technology Leaders in regulated spaces (Finance, Healthcare, Critical Infrastructure).
⚡ Key Takeaways & Strategic Vectors
- The Vibe Coding Trap: Building software on “vibes” and loose prompts creates code that is confidently written but structurally wrong. It fails to account for implicit system memory, hidden edge cases, and architectural constraints.
- The Spec as the Ultimate IP: True value no longer resides in the generated code itself (which is temporary and execution-based), but in the Specification. High-precision definition files ensure the AI operates with zero room for algorithmic misinterpretation.
- The Sandbox Mandate: Enterprise-grade AI agents must be heavily bounded by rigid architectural guidelines, token-efficiency controls, and Zero-Trust network principles.
- Compliance-by-Design: Unlike arbitrary vibe-coded scripts, spec-driven engineering ensures mathematical traceability. Every design choice and active function can be directly mapped back to a parent requirement—a non-negotiable metric for highly regulated environments.
Most teams using AI coding agents are not doing agentic software engineering. They are doing expensive prompt guessing at scale. There is a difference, and it matters more than the tool you picked.
The tooling conversation has been loud. Claude Code from Anthropic. ChatGPT Codex from OpenAI. GitHub Copilot, Cursor, Windsurf. A new agent lands in your inbox every other week. Every vendor promises 10x productivity. Every team I speak with reports impressive demos and underwhelming production outcomes. The gap between those two is not a tool problem. It is a discipline problem.
Spec-driven agentic software engineering is what closes that gap. This article explains what it is, why it is categorically different from vibe coding, and what it means for the managers who are responsible for the systems that need to keep running once the demo is over.
What Vibe Coding Actually Is
Andrej Karpathy coined the term in early 2025. He described it generously: you describe what you want, the model writes it, you accept it, maybe glance at it, mostly just keep prompting. Fast. Fun. Good for prototypes. Karpathy’s framing was honest about the limits. Most adopters missed that part. He noticed that high-quality code actually required more specifications and guardrails.
Vibe coding is one-shot prompting with no plan, no defined architecture, no stated quality constraints, and no validation loop. The agent picks the most plausible implementation, which is rarely the same as the correct one for your context. It does not know your security standards. It does not know your preferred patterns. It does not know whether you use PostgreSQL or DynamoDB, or why. It fills those gaps with its training data, which means it fills them with the average of the internet.

The Stack Overflow Developer Survey 2025 found that while 84% of developers now use or plan to use AI tools, only 33% trust their accuracy, and positive sentiment dropped from over 70% in 2023-2024 to 60% in 2025. Adoption is not the bottleneck. Confidence in what agents produce is. That is a specification problem, not a model problem.
At the production scale, vibe coding exhibits three failure modes that compound each other:
- Intent drift. “Add login” is wildly underspecified. The agent picks reasonable defaults, and those defaults rarely match what the team actually needed.
- Context decay. As the codebase grows past the agent’s effective context window, it forgets earlier architectural decisions and silently contradicts them. LLMs generate vulnerable code at rates ranging from 9.8% to 42.1% across benchmarks. Production repositories with AI-introduced issues had topped 110,000 by early 2026.
- Unverifiable output. Without explicit acceptance criteria, there is no principled way to know whether the agent’s code is right. Code reviews become a test of who can spot problems fastest under pressure. That is not a quality gate. It is a lottery.
What I Got Wrong First
I will be direct about my own experience here, because I think it is more useful than another clean narrative.
When I first introduced AI coding tools to our workflow, I was disappointed. Not by the quality of individual outputs, which were often impressive. I was disappointed because the system produced parts without a whole. Every agent’s decision was locally reasonable and globally incoherent. The AI had no knowledge of our preferred architecture, our design patterns, our non-functional requirements, our stance on library dependencies, or our quality bar. It simply took the first viable solution. Which is not the same as the right solution.
The code worked. It just did not belong to anything.
What I failed to understand at the time was that the agent was not the problem. The absence of a formalized engineering context was the problem. We had never written down our architecture decisions, our patterns, our NFRs in a form that a machine, or frankly, a new team member, could act on. The AI just made that gap impossible to ignore.
Reading about spec-driven development was the turning point. Not because it offered a clever new tool. Because it forced us to do something we should have done regardless: formalize our processes, document our architecture, define our quality standards, and put all of it in version-controlled files that live next to the code. The AI did not create that discipline. It made the absence of it cost us something.
What Spec-Driven Agentic Software Engineering Actually Is
Spec-driven development (SDD) is the engineering discipline of treating structured specifications as the primary artifact of software delivery. The spec is the sovereign document from which implementation is derived, verified, and governed. Code is the build output, not the source of truth.
The foundational SDD paper on arXiv (February 2026) describes it this way: the spec captures intent, behavior, edge cases, and non-functional requirements in a structured form that both humans and language models can read and act on.
In practice, that means a four-phase workflow. Every major framework has independently converged on the same pattern: GitHub Spec Kit, AWS Kiro, Anthropic’s Claude Code best practices, and OpenAI’s Symphony orchestrator.
- Specify. Author a structured document covering functional requirements, non-functional requirements, acceptance criteria, edge cases, and out-of-scope boundaries. This is the slowest phase. It is also where the entire downstream quality of your system is determined.
- Plan. Translate the spec into a technical plan: architecture choices, data models, API contracts, library selections constrained by your project constitution. The plan encodes how; the spec encodes what.
- Tasks. Decompose the plan into atomic, independently executable units. Each task has a single objective, defined inputs, defined outputs, and an acceptance check. An agent is effectively a fast junior engineer. Task lists should be written accordingly.
- Implement. The agent executes. Humans review at every phase boundary, not at the end. The spec is always the reference point for what “correct” means.
AWS Kiro documents real cases where 40-hour features were shipped in under 8 hours of human time when authored as specs first. GitHub reports roughly an order-of-magnitude reduction in “regenerate from scratch” cycles compared to ad-hoc prompting. These are not marginal gains. They are the difference between a workflow and a habit.
The Distinction That Matters: A Direct Comparison
For IT managers, engineering managers, and business leaders who need to have this conversation with their teams, here is the operating difference:
| Dimension | Vibe Coding | Spec-Driven Agentic Engineering |
|---|---|---|
| Source of truth | The prompt | The specification document |
| Architecture | Agent decides | Human-defined, documented, version-controlled |
| NFRs | Assumed from training data | Explicitly specified upfront |
| Context for agent | Current conversation | Constitution + spec + plan |
| Validation | “Does it run?” | “Does it satisfy the acceptance criteria?” |
| Test automation | Optional, ad-hoc | Generated from spec, mandatory |
| Continuous delivery fit | Low (output is unpredictable) | High (spec is the contract) |
| Governance | None | Full audit trail from spec to PR |
| Scale | Degrades with complexity | Designed for complexity |
| Suitable for | Prototypes, exploration | Production systems, regulated environments |
The confusion between these two approaches is not semantic. It has budget consequences, architectural consequences, and security consequences. Vibe coding wearing an enterprise hat is still vibe coding.
Architecture and Design Patterns Belong in the Spec
This is the section most teams skip. It is also where most AI-generated systems fall apart.
When you introduce an agentic coding workflow, every decision the agent makes that you have not specified becomes a guess. That includes your architecture. Your preferred design patterns. Your stance on microservices versus modular monoliths. Your API versioning strategy. Your logging and observability approach. Your dependency policy.
The agent will make those decisions. It will make them based on its training data, which means it will make them based on the average of the internet in 2024. That average does not know your system.
The solution is a project constitution: a version-controlled Markdown file (typically CLAUDE.md in Claude Code, AGENTS.md in ChatGPT Codex, or .specify/memory/constitution.md in GitHub Spec Kit) that defines your engineering context explicitly. This file is loaded with every agent session. It is the first thing any agent reads. It governs every implementation decision downstream.
A well-structured constitution contains:
- Architecture decisions. “We use a hexagonal architecture. Domain logic does not depend on infrastructure. All external integrations are behind interfaces.” One sentence. Binding.
- Design patterns. “We use the repository pattern for data access. We do not use active record outside of legacy modules.” No guessing. No drift.
- Non-functional requirements. Performance budgets, security requirements, accessibility targets, SLA commitments. These are first-class constraints that every implementation decision must respect, not an afterthought.
- Dependency policy. “No new runtime dependencies without an Architecture Decision Record (ADR). Security vulnerabilities in dependencies block deployment.” An agent that installs random packages without constraint is a supply chain risk, not a productivity tool.
- Testing and CI/CD requirements. “All new code requires unit tests and integration tests. Coverage must not drop below current baseline. All commits trigger the full pipeline.” This connects the spec directly to your continuous delivery practice.
- Code style and conventions. Language version, formatting rules, naming conventions. Boring. Essential.
The constitution is not documentation. It is a governance mechanism. Once it exists, every agent working on your codebase operates within your engineering culture rather than against it. It is also the document that makes onboarding new engineers, human or AI, measurably faster.
Augment Code’s analysis of spec-driven workflows notes that the EU AI Act, coming into full effect in August 2026, requires high-risk AI systems to maintain documentation of design decisions and validation criteria. Your constitution is also your compliance artifact. The teams that build it now will not be scrambling to reconstruct it later.
The Productivity Trap Nobody Talks About
My second hard lesson from this transition, and I have watched it happen in every team that picked up agentic tools. Agentic software engineering was increasing the quality. That part was real, and it showed up immediately: better test coverage, more consistent patterns, fewer obvious bugs. But it was not increasing productivity. For weeks, I could not figure out why.
Then I watched how engineers were actually using the tools. They were watching. The AI was generating, and they were sitting in front of the terminal, following along, occasionally redirecting, waiting for the output. An engineer babysitting an AI agent is an engineer who is not doing anything else.
The productivity unlock for async AI tools like Claude Code and ChatGPT Codex is not that they write code faster while you watch. It is that they write code while you do something else entirely. Codex runs in the cloud, clones your repository, executes against a task spec, and opens a pull request while you are in a design review. Claude Code runs in plan mode, executes a task list, and returns with evidence (test output, diffs, commit history) that you review at a time you choose.

Anthropic’s analysis of approximately 400,000 Claude Code sessions between October 2025 and April 2026 found that Claude Code users now spend an average of 20 hours per week using the tool, and that the greater the domain expertise a person brings, the more work Claude does per instruction. Experts delegate more, babysit less, and the output quality is higher.
OpenAI’s Symphony orchestrator, built internally by OpenAI’s own engineering team, makes this concrete. They observed that engineers could comfortably manage three to five agent sessions before context switching became painful. Symphony solved this by making the issue tracker the control plane: every open task gets an agent, agents run continuously, and humans review results. The outcome was a 500% increase in landed pull requests on some teams. Not because anyone wrote more code. Because nobody was watching.
The shift in mental model: stop thinking of the agent as a tool you operate. Start thinking of it as work you delegate, with a proper brief, defined quality criteria, and a review process. That brief is your spec.
Governance, Validation, and Continuous Delivery
Spec-driven agentic engineering does not replace your continuous delivery pipeline. It makes the pipeline enforceable.
Without a spec, CI/CD is a set of technical gates: linting passes, tests pass, build succeeds. Those gates tell you the code is syntactically and mechanically acceptable. They do not tell you whether it does what it was supposed to do, whether it respects the architecture it was supposed to fit into, or whether it meets the performance and security requirements it was supposed to satisfy.
With a spec, the acceptance criteria become the definition of done for your pipeline. Your test suite is generated from the spec. Your review process validates implementation against the spec. Your deployment gates verify that the spec was actually followed, not just that the code compiles.
The ThoughtWorks Technology Radar (Volume 33, 2025) places SDD in the “Assess” ring and specifically warns about the antipattern of heavy up-front specification and big-bang releases. The point is not to return to waterfall. The point is to have a living, version-controlled spec that evolves with the product, where changes to the spec trigger code regeneration, not document updates followed by verbal briefings.
In practice, that means:
- The spec lives in your repository alongside the code it describes.
- Architecture Decision Records (ADRs) document why architectural choices were made, not just what they are. Agents read them. New engineers read them. Both benefit.
- Non-functional requirements are expressed as executable criteria: performance budgets as benchmark targets, security requirements as automated scan thresholds, not as prose ambitions.
- Every agent-generated PR references the spec it was implementing. Reviewers compare implementation to spec, not implementation to intuition.
- When requirements change, the spec changes first. Code follows. The direction is always spec to code, never code to spec rationalized after the fact.
This is what agentic engineering looks like when it is actually engineered.

The Tools: Claude Code, ChatGPT Codex, and the Ecosystem
The tooling landscape has stabilized enough to give practical guidance.
- Claude Code (Anthropic) is a terminal-based agentic coding environment that supports spec-driven workflows through its
CLAUDE.mdmemory system, Plan Mode, subagents, and hooks. Anthropic’s best practices documentation explicitly separates research and planning from implementation and recommends verification subagents that check agent outputs against stated requirements rather than trusting the implementing agent to grade its own work. Claude Code integrates natively with GitHub Spec Kit, the open-source SDD framework that has emerged as the model-agnostic standard. - ChatGPT Codex (OpenAI) is a cloud-based agent that clones your repository into a sandboxed environment, executes tasks, and opens pull requests asynchronously, while you are doing other work. Its
AGENTS.mdfile serves the same role asCLAUDE.md: the project constitution that every agent action respects. Codex is optimized for parallel, batch-style work such as dependency upgrades, test coverage expansion, and large refactors, where the task is well-defined and independently testable. OpenAI reports over 5 million weekly active users as of June 2026, with knowledge workers now making up roughly 20% of that base. - GitHub Spec Kit is the specification layer that sits above both tools. Open-sourced in September 2025, it provides the
/constitution,/specify,/plan,/tasks, and/implementslash commands that structure the four-phase SDD workflow. It is model-agnostic: the same spec works with Claude Code, Codex, Copilot, and Cursor. For teams that want to avoid vendor lock-in at the workflow level, this is the practical choice. - AWS Kiro takes a more integrated approach: a standalone agentic IDE where spec, plan, tasks, and code share one workspace, with automated hooks that enforce testing, linting, and security scanning after every agent action. Best suited for AWS-native teams.
The model race between these platforms is, at this point, a distraction. As Anthropic noted at Code with Claude 2026, the bottleneck for production agent systems is not model capability. It is the infrastructure around the model. The spec is that infrastructure. A good specification also reduces the amount of time and tokens, for the AI searching for an answer and exploring alternatives. This is essential in a time with high token costs and limited infrastructure availability.
What to Do This Quarter
Three decisions. Not ten.
- Write your constitution before you do anything else. Open a file called
CLAUDE.mdorAGENTS.mdat the root of your most important repository. Document your architecture, your design patterns, your NFRs, your dependency policy, your testing requirements. One afternoon of work. It will govern every agent action in that codebase from this point forward. If you do not have documented architecture and NFRs, write them now. The AI just made that work urgent. - Replace “let the agent figure it out” with a spec phase. For any feature that will go to production, require a specification document before the agent touches code. It does not need to be long: a few hundred words for a modest feature, perhaps a thousand for something significant. What it needs is functional requirements, non-functional requirements, acceptance criteria, and out-of-scope boundaries. That document is the brief you would give any engineer. Start giving it to agents too.
- Audit your engineers’ actual workflow. If your team is watching AI generate code, you have not changed how software gets built. You have just added an expensive observer role. The productivity model for agentic tools is asynchronous delegation, not supervised execution. Run the agent on a well-specified task, go do something else, return to review evidence. If that is not how your team works yet, the bottleneck is not the tool. It is the workflow.
The hard question underneath all of this is not which AI coding tool to buy. It is whether your engineering organization is disciplined enough to use any of them well. Vibe coding exposes the answer fast.
Leave a Reply